








Research
The Research Is Clear: Coding Agents Are Bottlenecked by Search, Not Coding Ability
A survey of recent research on why AI coding agents fail — and why the answer is almost always retrieval, not generation.
Fast, parallel subagent for search. #1 on SWE-Bench Pro.
Apply AI-generated edits at 10,500+ tokens per second. Instant code updates, zero lag.

Embeds a video of an AI agent testing your changes right in your GitHub PR. Catch UI bugs before your users do.
Apply AI-generated edits at 10,500+ tok/s. Instant code updates, zero lag.
Fast, parallel subagent for search. #1 on SWE-Bench Pro.
AI browser testing for your PRs. Embeds video recordings directly in GitHub.
Lightning-fast 10,500 tokens/sec edits —10x faster than alternatives
Model Processing Speed Comparison (Tokens/s)
Enterprise-grade 98% accuracy ensures your code works right the first time.
Model Accuracy Comparison (%)
Deploy Morph on your own infra - on-prem or cloud.
Flexible, high-capacity rate limits.
99.9% uptime SLA with top-tier support .
Ready-to-sign agreements for enterprise compliance.
A survey of recent research on why AI coding agents fail — and why the answer is almost always retrieval, not generation.
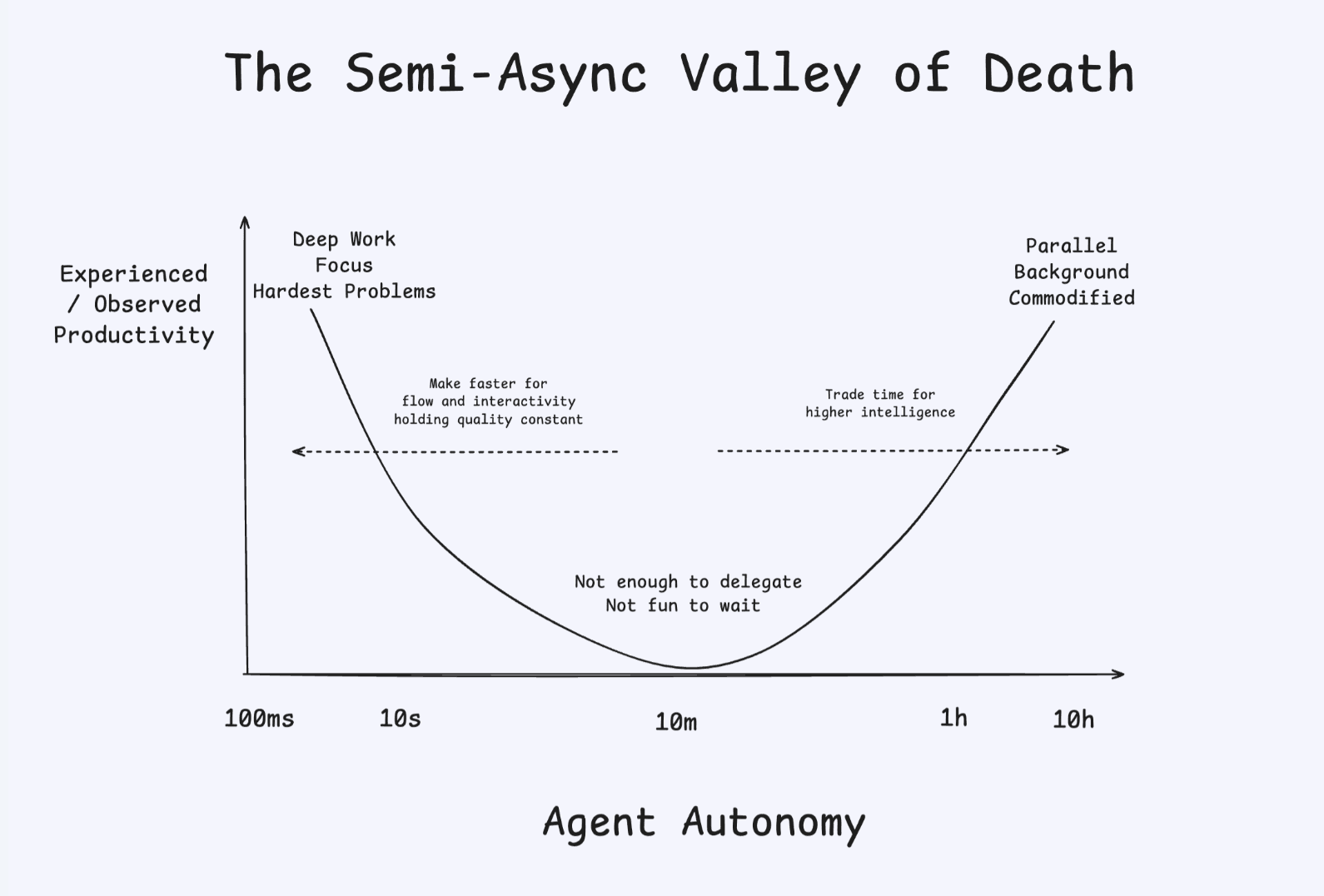
As coding agents run for hours and days, two things change: agents need real code search to navigate, and human oversight moves from the IDE to the pull request.

How we built a reward policy that trains browser agents to verify UI changes through code coverage and component engagement.
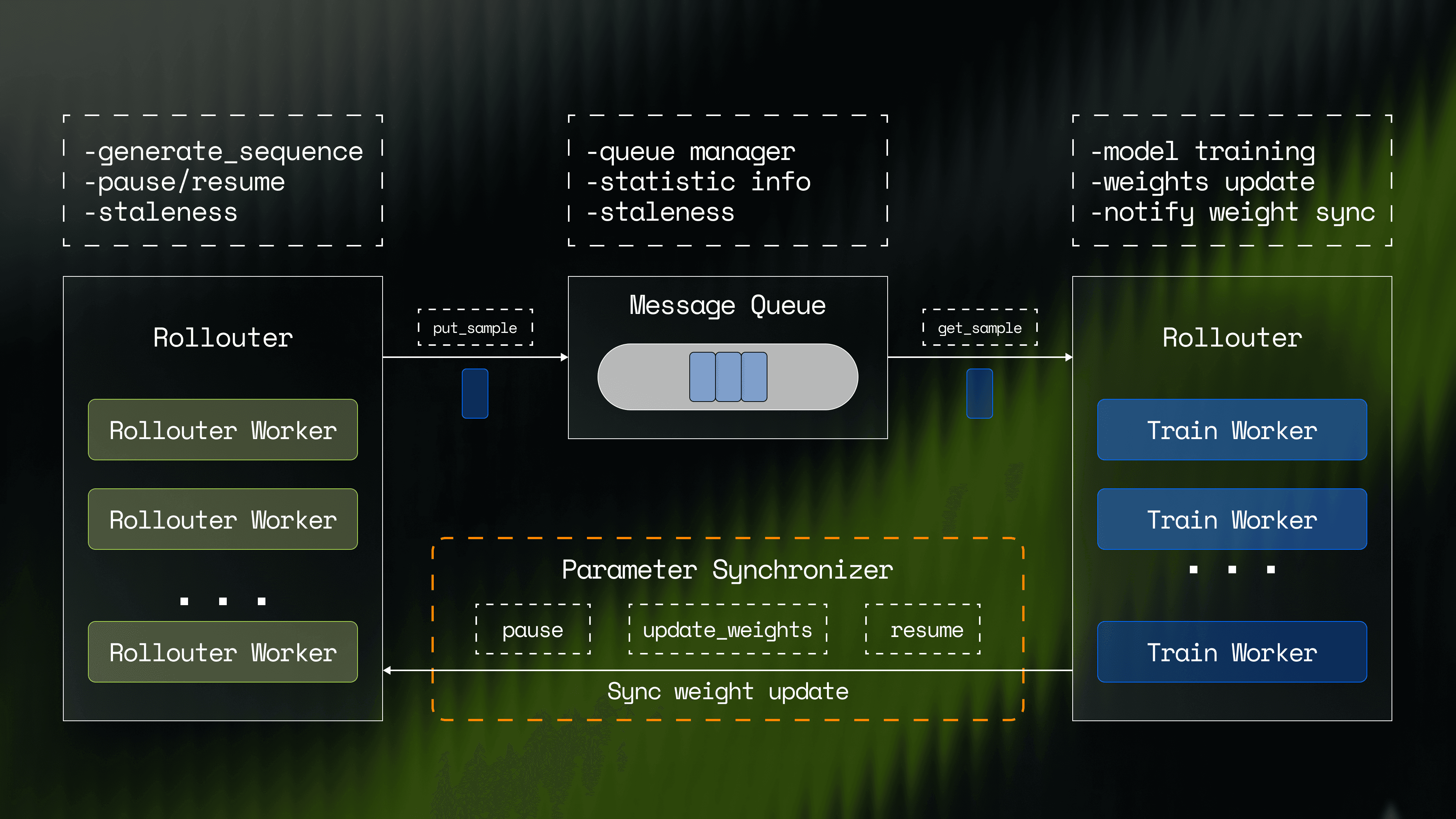
How we trained WarpGrep, a fast context model specialized in doing the dirty work of code search, using highly parallel code retrieval that matches frontier coding models while taking 5x less time
Startups should use off-the-shelf IDEs. Enterprises have massive alpha in custom integrations. Here's the decision framework.
Stop waiting 15 seconds for edits. Stop searching the same files over and over.
Critical takes on the latest in codegen.

Scale AI's benchmark for coding agents: 1,865 tasks across 41 repos. Leaderboard, scores, and why WarpGrep v2 lifts every model to #1.

Real data on when Codex destroys Claude Code and when it doesn't. Token economics, failure modes, and which $20/month actually delivers.

Every serious Cursor alternative benchmarked: Claude Code, Windsurf, Cline, Copilot, Aider, Codex, and OpenCode.

Claude Opus 4.5 leads SWE-bench at 80.9%. Grok 4 hits 81%. Scores, API pricing, speed, and why the harness matters more than the model.

How coding agents actually work, what separates harnesses from models, and where the field is headed.

Set up Playwright MCP in Claude Code, Cursor, or Codex. MCP vs CLI token costs and Stagehand comparison.

Native install, Homebrew, npm. Auth, CLAUDE.md, MCP setup, and troubleshooting.

Why LLMs degrade as context grows. 30%+ performance drop from lost-in-the-middle, and how subagent isolation reduces context rot by 70%.
The difference between a prompt and an agent that works. How to structure context so coding agents stay coherent across long sessions.

Technical analysis of AI coding agent harness architectures. Go-based OpenCode (75+ providers) vs Rust-based Codex (GPT-5).
Every head-to-head comparison in one place. Cursor, Claude Code, Copilot, Windsurf, Codex, Aider, Cline, and more.

Search-replace blocks with git merge syntax: limitations, accuracy issues, and why semantic editing achieves 98% vs 70% success rates.